
Op vrijdag 11 januari was ik te zien in een uitzending van Een Vandaag over robots. De vraag was: Kunnen robots poëzie schrijven? Ik gebruikte daarvoor het programma ‘Bot or not!’ Zie https://www.npostart.nl/eenvandaag/11-01-2019/AT_2109344 (vanaf minuut 10:20).

1. ‘Kunnen robots literaire romans schrijven’ is niet zozeer een vraag over robots, maar over algoritmes. De vraag zou je dan ook kunnen herformuleren als: kunnen we een algoritme/softwareprogramma schrijven dat literaire werken als verhalen, romans, gedichten of essays zou kunnen voortbrengen die bij lezing (door mensen) niet door de mand zouden vallen en gewaardeerd worden om hun inhoud, structuur en stijl?

2. Al in de jaren tachtig werd er beweerd dat een softwareprogramma een literair boek had geschreven, maar dat bleek niet meerdan een gepersonificeerde roman (Evelyn Brown, Swan Publishing, Placentia, Californië, 1988). Een stukje verder kwam Scott French, de schrijver van Just This Once, al is nooit helemaal opgehelderd wat nu precies de rol van de software en wat de rol van de schrijver zelf was.
3. Inmiddels zijn er tal van bots – gedichtenbots, sixwordstorybots – die je op Twitter kunt volgen: dadabots, rijmbots, kleurengedichtenbots, ‘robot poetry from the moon’.

Soms hebben deze programma’s hele bijzondere uitkomsten die met enige verbeelding ook aan menselijke dichters zouden kunnen worden toegeschreven. Bijvoorbeeld:
The spaceship is long gone
Robot must worry
worry, robot, worry
But where??
worry, worry, worry
Robot, forever worry’
Voor een overzicht van poëziebots zie onder andere deze verzameling: https://botwiki.org/bot/?tags=poetry.
Vraag is natuurlijk of je dit soort ‘poëzie’ als mens wil lezen. En kun je onderscheiden wat er door software wordt gemaakt en wat door mensen is geschreven? Deze laatste vraag heeft zelfs al een spelletje opgeleverd: bot or not?. Wie kan de echte dichter onderscheiden van het poëzie-algoritme?
4. Softwareprogramma’s die zelf romans schrijven zijn er ook, maar de resultaten ervan zijn nog niet om over naar huis te schrijven. Meestal vallen de voortbrengselen ervan binnen een paar zinnen of alinea’s door de mand – zelfs als ze zich voordoen als een soort postmoderne vertellingen.
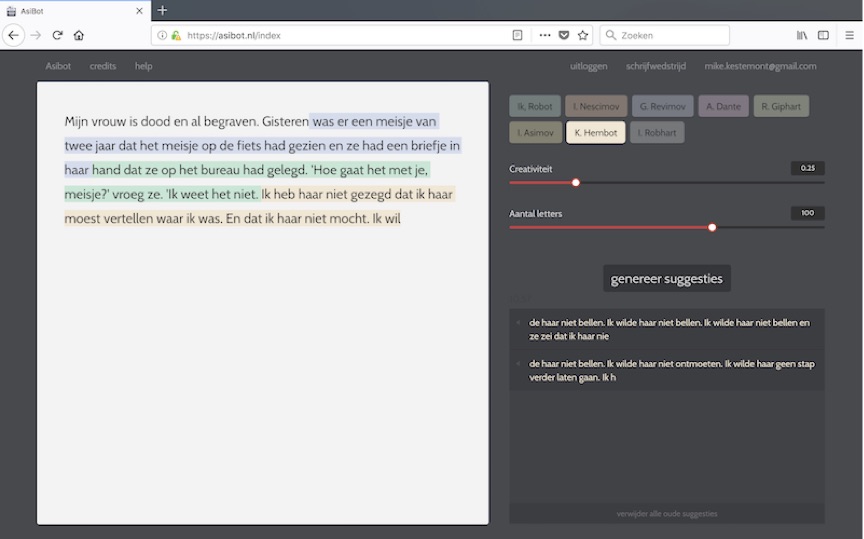
In 2017 kwam bijvoorbeeld de Nederlandse ‘asibot’ in het nieuws toen deze voor de campagne ‘Nederland Leest’ een verhaal had geschreven ‘samen met Ronald Giphart’ (zie: https://www.nederlandleest.nl/vanaf-6-november-zelf-schrijven-met-asibot/). Het softwareprogramma werd gemaakt door taaltechnoloog Folgert Karsdorp, samen met onderzoekers van de Universiteit van Antwerpen en het Meertens Instituut (zie www.asibot.nl). Karsdorp liet meteen al weten dat een zelfstandig verhaal laten schrijven door een bot er nog niet in zit. “Zover is de technologie nog lang niet,” zei Karsdorp op Nemo Kennislink. “Een lopende tekst kan hij nog wel genereren, maar een coherent geheel is het niet.” Vandaar ook zijn idee: zou het niet veel leuker zijn om een Nederlandse schrijver een interactie aan te laten gaan met een computer?
5. Programmeurs, redacteuren, kunstenaars en schrijvers zijn dus nog steeds op zoek naar betere literatuurgenererende software. Er is inmiddels zelfs een speciale maand waarin programmeurs/codeschrijvers worden aangemoedigd een romangenerator te bouwen: de National Novel Generation Month (NaNoGenMo), ooit begonnen door kunstenaar/programmeur Darius Kazemi.

Een van de ‘hits’ van dit project was World Clock van NickMontfort: een openingsalinea van een roman, die zich om de minuut aanpaste, met telkens andere personages en locaties (dit programma werd geschreven in de recordtijd van vier uur!). Het boek werd later dat jaar uitgegeven door Harvard Press. Kazemi vond het resultaat wel aardig maar zag zelf de beperkingen ook heel goed: zo’n boek ga je niet in z’n totaliteit lezen, vond hij, maar je bladerde er doorheen.
Bij een andere romanalgoritme liet men ‘personages’ in een huis rondwandelen en met elkaar converseren; de conversatietekst werd uit Twitterberichten gehaald, op basis van minimale aanwijzingen. Een voorbeeld van zo’n conversatie: ‘Wat eten we?’ ‘Eten is mijn favoriete bezigheid.’ Nadien werden nog fijnzinniger programma’s geschreven, waarin de bezigheden en gedachten van personages werden opgeroepen op diverse momenten op een dag, maar ‘it reads like crap’, zoals de programmauteur zelf toegaf.
Dat laatste is nog steeds de bottle neck bij literatuuralgoritmes: een zinnetje of een alinea kan interessant zijn en nog wel enigszins lijken op een tekst uit een roman, maar lees je verder, dan weet de lezer meteen dat dit geen vormexperiment van een postmodernistische auteur is, maar een gebrekkig softwareprogramma. De Turingtest voor romans is nog niet gehaald en dat zal ook niet snel gebeuren, verwacht men.


Het dichtst in de buurt van zo’n geslaagde roman-Turingtest komt in feite het procédé dat programmeur Greg Borenstein toepaste. Zijn doel was een soort grafische novelle te maken en daarvoor gebruikte hij een groot corpus aan detectiveromans die je bij het Gutenbergproject kunt vinden. Op die teksten liet hij een scriptje los waarin hij zinnen zocht met woorden als question, murderer, witness, saw, scene, killer, weapon, clue, accuse of reveal. Die zinnetjes voerde hij vervolgens in Flickr in, waardoor hij foto’s vond. Die haalde hij door een zelfgeschreven ‘film noir’/’manga’-filter, plaatste het zinnetje eronder, et voilà: je hebt een soort Dick Bos-achtig plaatje dat je verbeelding meteen aan het werk zet. Bottom line is wel dat het meer een soort procédé is dan een algoritme, alhoewel je van het een het andere zou kunnen maken. Een heel verhaal hiermee maken is weer een volgende stap: het procédé werkt tot nu toe alleen met losse plaatjes. Een menselijke redacteur kan ze misschien in een bepaalde logische volgorde zetten, maar voor een softwareprogramma is dat nu nog te lastig.
6. Er is ook een automatische autobiografieschrijver: GhostWriter, en dat is volgens de makers een nieuw literair genre. Die makers zijn Italiaanse kunstenaars, onder leiding van Salvatore Iaconesi, Oriani Persico en Erica Scourti, verenigd in ‘Art is Open Source’ in samenwerking onder andere met het Goethe Instituut. De data voor deze auto-biografie worden via algoritmes verzameld en in verschillende vormen gepresenteerd (Zie deze link en vanaf 1:20 op https://www.youtube.com/watch?v=5I4EbdDDHe4). De resultaten worden tentoongesteld, maar niet in boekvorm uitgegeven en dat is al een teken dat de uiteindelijke producten nog steeds niet echt fijn leesvoer vormen.
7. Het knelpunt is vrijwel altijd taalgeneratie: het maken van interessante, zinvolle, spannende zinnen, alinea’s, scènes en hoofdstukken. Dat kan software nog niet. Er zijn wel succesvolle ‘schrijfprogramma’s ontworpen de afgelopen decennia en sommige worden zelfs voor professionele doeleinden gebruikt, maar vaak kan dit alleen binnen een heel afgeperkt genre met zeer beperkte doeleinden.
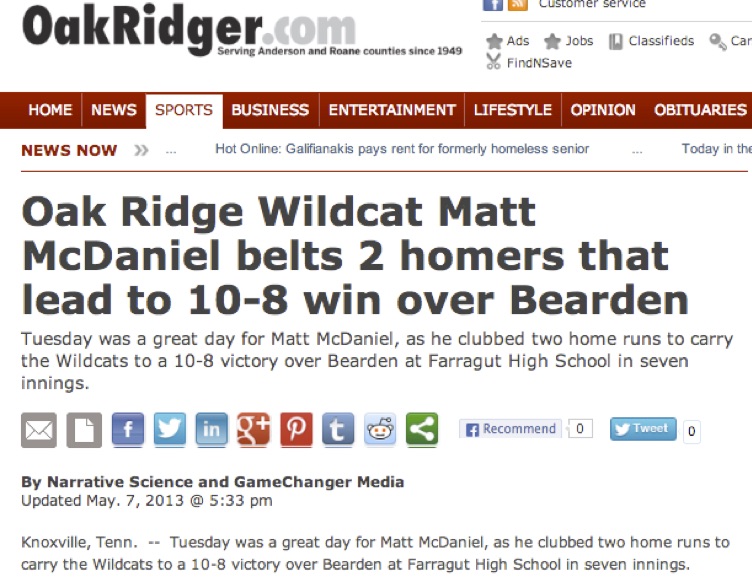
Zo maakt de software van Narrative Science een journalistiek sportbericht van sportuitslagen: het duwt gegevens in door journalisten en redacteuren voorgestanste mallen (formats) en zorgt er zo voor dat er honderden sportberichten op sites en in kranten terecht kunnen komen, zonder tussenkomst van menselijke redacteuren. Het zijn een soort journalistieke bots, maar wel met een zeer beperkte vocabulaire.
Wil je software die hele zinnen kan schrijven, dan heb je NaturalLanguage Generation-software nodig, zoals die bijvoorbeeld nu al aanwezig is in hulp- en conversatiesoftware (bots) als Amazon’s Alexa, Apple’s Siri en Google Assistent. Zeker nu NLG ook wordt gezien als de volgende stap in e-commerce en business intellegence, zou het wel eens hard kunnen gaan met de ontwikkeling van taalbots, hoewel de beperkingen van taalgeneratie zich nog steeds laten gelden: voor beurs-,weer- en sportberichten kan de software zich redelijk redden, maar vrijere genres als poëzie en romans blijken lastiger. Een algoritme een rapport of zelfs een goede verkoopbrief laten schrijven is momenteel nog een stap te ver.

8. Toch zijn er aanwijzingen dat algoritmes wel degelijk een rol kunnen spelen in de literatuur. Wil je bijvoorbeeld een bestseller schrijven dan kun je volgens Jodie Archer in haar boek The Bestseller Code gebruik maken van algoritmes. “Together with Matthew Jockers, an expert on text mining, she has written an algorithm that can tell whether a manuscript will hit the New York Times bestseller list with 80% accuracy.” Maar liefst 280.000 ‘datapunten’ werden gedetecteerd in een boek die van belang zijn bij het bepalen of een boek een bestseller zal worden of niet. 1% daarvan (2.800) is verantwoordelijk voor de bestseller, bijvoorbeeld korte zinnen, verhalen met een duidelijke vertellersstem, een beperkte woordenschat en emotionele spanning die telkens van hoog naar laag schiet en menselijke intimiteit (‘human closeness’). (Zie: The Guardian).

9. Ruwweg zijn er twee wegen die succesvolle codeliteratuur op zou kunnen gaan. De eerste is de gestructureerde algoritmische methode: zoek de regels waaraan ‘literatuur’ zou moeten voldoen en laat hier variabelen op los. Dat deed bijvoorbeeld Vladimir Propp in het begin van de 20e eeuw al met zijn morfologie van het Russische volkssprookje (zie bovenstaande formule).
En ook de ‘reis van de held’, die door Joseph Campbell werd beschreven als het DNA van alle verhalen, zou als Transformationeel Generatieve Grammatica van de literatuur kunnen dienen (net als Jan Veldman’s De 36 dramatische situaties).

Op basis van dit soort literaire regels en variabelen kun je een verhaal opbouwen en de voortgang bewaken. En wat je voor Russische volkssprookjes kunt doen, kun je ook voor streekromans, literaire thrillers en misschien zelfs psychologische romans doen: heb je eenmaal de structuurbepalende elementen (de morfologie) geanalyseerd, dan heb je daarmee een literatuurgenererend instrument in handen.
De tweede richting is big data: analyseer grote hoeveelheden literaire teksten en presenteer die volgens bepaalde regels in een nieuwe vorm, volgorde en/of structuur. Zo werken de meeste poetrybots en zo werkt Asibot ook. En het is ook een beproefd literair procédé. Dat begon in de jaren twintig van de vorige eeuw met krantenstukjes in beschrijvingen (John DosPassos, Alfred Döblin, James Joyce) en dit werden op zeker moment zelfs ready-mades of objet trouvés: complete stukken tekst van reclames, voorlichtingbrochures of krantenartikelen. Zie bijvoorbeeld het gedicht ‘Staat verzekerd’ van Alfred Schaffer uit Schuim uit 2006 (de sterretjes staan in de tekst, de functie ervan is niet helemaal duidelijk):
De kans dat er een terrorist* in uw wijk woont, is erg klein.
Mensen worden niet van de ene op de andere dag terrorist.
Heeft uw kind veel aandacht voor radicale ideeën?
Praat daar dan over met hem of met haar.
Mensen die zich verdacht* gedragen, worden scherp in de gaten gehouden.
Ook mensen die geen toekomst* voor zichzelf zien
kunnen een risico vormen. Meer dan we kunnen vertellen.
Daarom is er speciale aandacht voor plekken* waar radicalisering ontstaat.
We luisteren af. We infiltreren. We verzamelen en bestuderen
informatie over verdachte personen en groepen.
Wat de overheid wel en niet mag, is in wetten* vastgelegd.
Om terrorisme beter te kunnen bestrijden, worden wetten aangepast.
De Tilburgse kunstenaar Paul Bogaers publiceerde in 2007 de roman Onderlangs die met geheel samengesteld was uit zinnen uit zo’n 250 andere romans. Bogaers had zelf geen enkele zin geschreven alles aan elkaar geplakt. Hij haalde er zelfs een literaire-prijsnominatie mee.
Het punt hierbij is dat er altijd een menselijke redacteur aan te pas komt, die allereerst de tekst(en) geschikt moet vinden en vervolgens op het juiste moment moet afbreken (Schaffer) of aan elkaar moet plakken (Bogaers). Dat procédé kun je blijkbaar met de huidige stand van de techniek nog niet aan software overlaten, zelfs als het een combinatie van Artificiële Intelligentie, zelflerende algoritmes en big data is.
10. Misschien is de beste oplossing een vermenging van beide richtingen: literair-morfologische algoritmen die met grote hoeveelheden literaire data (zinnen, alinea’s) kunnen werken. Kwaliteit (literaire structuur, thematiek, spanning, personages) en kwantiteit (woorden, zinnen, alinea’s) moeten zo verenigd worden.
Uiteindelijk komt ook de vraag naar het nut boven: waarom zou je dit willen? Wie moeten deze computergegeneerde romans lezen? En zou het niet interessanter zijn om met de mogelijkheden van nu en straks nieuwe genres en procédés te ontdekken, die wel door lezers gewaardeerd worden en die niet of nauwelijks door mensen gemaakt kunnen worden. Zoals de generatieve muziek die door o.a. Brian Eno en anderen in app-vorm verkrijgbaar is: repetitief en eeuwigdurend. Gaan wij dat lezen? Hoe vaak? Hoe lang? Of wordt het leesvoer voor de bots zelf, in hun vrije uurtjes?